通过show status了解各种SQL的执行频率
mysql>show status like 'Com_%';
Com_select:执行SELECT操作的次数。一次查询累加1.
Com_insert:执行INSERT操作的次数。对于批量插入的INSERT操作,只累加1。
Com_update:执行UPDATE操作的次数。
Com_delete:执行DELETE操作的次数。
其他参数
Innodb_rows_read:执行SELECT查询返回的行数。
Innodb_rows_inserted:执行INSERT操作插入的行数。
Innodb_rows_updated:执行UPDATE操作更新的行数。
Innodb_rows_deleted:执行DELETE操作删除的行数。
Com_commit:事务提交的情况。
Com_rollback:事务回滚的情况。
Connections:试图连接MySQL服务器的次数。
Uptime:服务器工作时间。
Slow_queries:慢查询的次数。
定位执行效率较低的SQL语句
1.通过慢查询日志定位
2.通过show processlist查看当前MySQL在运行的线程,包括线程的状态、是否锁表等。
可以实时查看SQL的执行情况,同时对一些锁表操作进行优化。
通过Explain分析低效SQL的执行计划
Possible_keys:表示查询时可能用到的索引。
Rows: 扫描行的数量。
看看是否有索引,或者出现全表扫描。

索引的存储分类
MySQL中索引的存储类型只有两种BTREE和HASH,innoDB存储引擎支持BTREE。
对相关列使用索引是提高SELECT操作性能的最佳途径。查询使用索引最主要的条件是查询条件中需要使用索引关键字。
索引的使用
1.如果创建的是多列索引,那么只有当查询条件使用了多列索引最左边的列时,才会使用到索引。
| name | age |
|---|---|
| 张三 | 20 |
| 张三 | 30 |
| 张四 | 15 |
| 张四 | 60 |
比如学生表创建了多列索引(name,age),索引示意图如上所示。
如果查询条件使用(name, age)或者(name)都会使用到索引。
如果查询条件只有age,比如age = 15,则不会使用索引,因为上图中单看age列其实是无序的状态。
如果查询条件是name=张四 and age=15,则通过复合索引先快速找到张四,再在张四的所有记录里面,age是有序的,就可以快速找到15。
2.如果查询条件中有like关键字,后面如果是常量并且只有%号不在第一个字符,索引才会生效。
![]()
 索引生效
索引生效
因为一般创建索引时,也是从第一个字符开始进行排序来创建。对于‘3%’,引擎是可以使用索引的。
3.如果对大的文本进行搜索,使用全文索引而不是使用like '%...%'
MySQL 5.6后的InnoDB版本支持。只有char, varchar, text及其系列才可以建立全文索引。

4.如果列名columnA是索引,查询条件使用columnA is null将使用索引。
5.用or分割的条件,比如A or B,如果A有索引B没有,那么A索引也不会被使用。
其实就算A用了索引,也没有用。
性能从大到小的排列是system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
System
- 意思:表只有一行记录(等于系统表),且表使用的存储引擎(如 MyISAM)的统计信息是准确的。
- 通俗解释:就像一个只有一条记录的特殊表格,查询时直接就能定位到这一行,效率极高,但这种情况非常罕见。
const
- 意思:通过索引一次就找到了,常用于比较主键或者唯一索引。因为只匹配一行数据,所以很快。
- 通俗解释:比如你有一个按学号排序的学生名单,你要找学号为 1001 的学生,直接就能定位到,速度非常快。
eq_ref
- 意思:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
- 通俗解释:还是以学生名单为例,现在要找所有选修了某门特定课程(假设课程号是唯一的)的学生,对于每个课程号,只有一个学生与之对应,查询时能快速定位。
ref
- 意思:非唯一性索引扫描,返回匹配某个单独值的所有行。
- 通俗解释:比如要找所有姓“张”的学生,姓“张”的学生可能有很多个,数据库需要通过索引找到所有姓“张”的记录,效率比
const和eq_ref低一些,但仍然较快。
fulltext
- 意思:全文索引检索。
- 通俗解释:就像在文章中搜索包含某个关键词的内容,全文索引会专门为这种搜索优化,但一般场景下使用较少。
ref_or_null
- 意思:与
ref类似,但增加了对NULL值的匹配。 - 通俗解释:比如要找所有姓“张”的学生以及没有姓的学生(姓为
NULL),除了像ref一样查找姓“张”的学生,还要额外查找姓为NULL的学生。
index_merge
- 意思:表示使用了索引合并优化方法。
- 通俗解释:比如查询条件中有两个索引,数据库可能会分别使用这两个索引进行查询,然后将结果合并,就像同时用两个不同的线索去查找信息,最后把找到的结果整合起来。
unique_subquery
- 意思:InnoDB 特有,子查询中的查询结果字段与外层查询的主键字段一致时,可以使用
unique_subquery优化。 - 通俗解释:假设有一个子查询是查找某个学生的所有成绩,外层查询是查找这个学生的信息,如果子查询的结果字段(如学生 ID)与外层查询的主键字段一致,数据库就可以进行优化,提高查询效率。
index_subquery
- 意思:InnoDB 特有,子查询中的查询结果字段与外层查询的非主键字段一致时,可以使用
index_subquery优化。 - 通俗解释:和
unique_subquery类似,但子查询的结果字段与外层查询的非主键字段一致,数据库也会尝试进行优化。
range
- 意思:只检索给定范围的行,使用一个索引来选择行。一般就是在使用
between、>、<、>=、<=、in等操作符时,加上索引就会触发range。 - 通俗解释:比如要找年龄在 20 到 30 岁之间的学生,数据库可以通过索引快速定位到这个年龄范围内的记录,就像在电话簿中查找姓氏在某个字母范围内的联系人。
index
- 意思:全索引扫描,只遍历索引树,不查询表里的所有数据。这通常比
ALL快,因为索引文件通常比数据文件小。 - 通俗解释:比如要找所有学生的学号,数据库只需要扫描学号这个索引,而不需要去读取每个学生的完整信息,就像在目录中查找所有章节标题,而不需要阅读整本书。
ALL
- 意思:全表扫描,遍历全表以找到匹配的行。
- 通俗解释:就像在没有任何目录的情况下,要在一本厚厚的书中查找某个内容,只能一页一页地翻,效率最低。
- 需要在表中建立索引
- 不要在索引上做任何的操作
- 不等号(!= 、<>)要谨慎使用
- 尽量使用覆盖索引
- like查询要注意
- 字符串需要加引号
- UNION代替OR
- NULL或者NOT NULL的影响
- 尽量全值匹配
- 最佳左前缀法则
- 范围条件放最后面
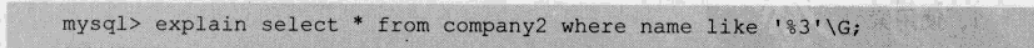{kind=link}
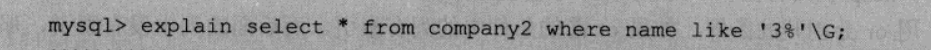{kind=link}
{kind=link}
{kind=link}