Apache Kafka 是一个分布式流处理平台。提供高吞吐量、低延迟的消息传递系统,适用于大规模数据流处理和实时分析。广泛应用于日志收集、监控数据聚合、流式数据处理等场景。
实现同步的请求响应模型。
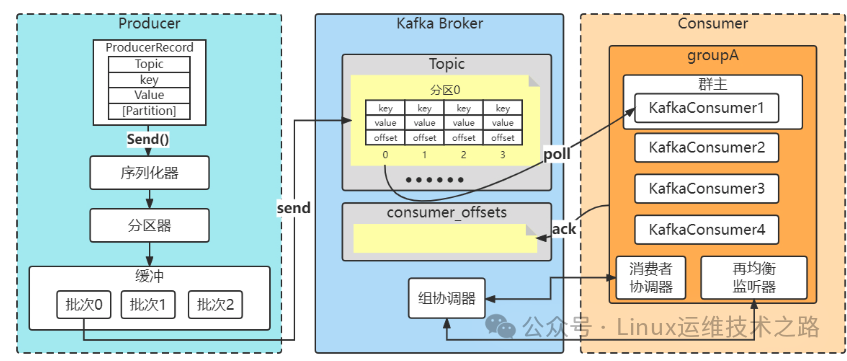
核心概念
- 1. Producer(生产者):负责将消息发布到 Kafka 集群中的某个 Topic。
- 2. Consumer(消费者):从 Kafka 集群中订阅 Topic,并消费消息。
- 3. Topic(主题):消息的分类或通道,生产者将消息发送到特定的 Topic,消费者从 Topic 中读取消息。
- 4. Partition(分区):每个 Topic 可以分为多个 Partition,Partition 是 Kafka 实现并行处理和扩展性的关键。每个 Partition 是一个有序的、不可变的消息序列。
- 5. Broker(代理):Kafka 集群中的每个节点称为 Broker,负责存储和传递消息。
- 6. Offset(偏移量):每个 Partition 中的消息都有一个唯一的 Offset,表示消息在 Partition 中的位置。
- 7. Consumer Group(消费者组):一组消费者共同消费一个 Topic 的消息,每个 Partition 只能被同一个 Consumer Group 中的一个消费者消费。
工作流程
- 1. 消息生产:Producer 将消息发送到指定的 Topic,Kafka 会根据 Partition 的策略(如轮询、哈希等)将消息分配到不同的 Partition。
- 2. 消息存储:每个 Partition 的消息会被持久化存储在 Broker 上,Kafka 使用顺序写入的方式提高性能。
- 3. 消息消费:Consumer 从指定的 Topic 和 Partition 中拉取消息,并通过 Offset 记录消费进度。Kafka 支持消费者组的概念,允许多个消费者协同工作。
- 4. 消息删除:Kafka 会根据配置的保留策略(如时间或大小限制)定期删除旧的消息。
特性
- • 高吞吐量:Kafka 能够处理每秒数百万条消息,适合大规模数据流处理。
- • 持久化存储:Kafka 将消息持久化到磁盘,支持消息的重放和容错。
- • 分布式架构:Kafka 是分布式的,支持水平扩展,能够处理大规模数据。
- • 多消费者支持:Kafka 支持多个消费者组同时消费同一个 Topic 的消息,互不影响。
{kind=link}