大模型部署工具ollma
Ollama是一个功能强大且易于使用的开源框架,它极大地简化了大型语言模型在本地机器上的部署和运行过程,为开发者和研究人员提供了丰富的工具和资源。
Ollama用来方便地部署大模型。
0基础实现本地部署 DeepSeek 的 DeepSeek-R1 模型教程
使用Ollama本地化部署DeepSeekDeepSeek-R1
安装路径:C:\Users\admin\AppData\Local\Programs\Ollama\ollama app.exe
Ollama Base URL: http://127.0.0.1:11434
cd C:\Users\admin\AppData\Local\Programs\Ollama
>ollama -v 查看安装是否成功
>ollama list 查看模型信息
>ollama run deepseek-r1:1.5b 通过命令行界面进行对话使用大模型
桌面容器管理docker desktop
方便容器化安装和管理open-webUI。
注册github tt202502/1-6(abc
安装路径:C:\Program Files\Docker\Docker\Docker Desktop.exe
docker desktop status
docker desktop start
running engine: waiting for the Docker API: context deadline exceeded
在命令行中输入"services.msc"打开服务管理器,查找并确保"Docker Desktop Service"已启动。
重启docker desktop。
交互界面open-webUI
和大模型的交互界面应用。
Ollama与Open WebUI结合,可以提供更丰富的交互体验。还有其他支持Ollama的webUI,如 AnythingLLM、Dify。
| webUI | 侧重 |
|---|---|
| AnythingLLM | 更专注于文档知识库与问答场景,自带向量检索管理,可“多文档整合”,接入 Ollama 后实现本地化问答。 可配置LLM提供商,向量数据库 |
| Dify | 功能多元,适合对话流管理、插件化扩展、团队协同等复杂需求。只要能在其后台正确配置 Ollama 地址,即可灵活调用。 |
| Open-WebUI | 定位纯聊天界面,支持多模型集成,你可以把它当做一个能“轻松切换模型、马上对话”的 Web 面板,如果只是想单纯体验 Ollama 的生成效果,Open-WebUI 是最方便的。 |
open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...) (github.com)
docker run -d -e HF_ENDPOINT=https://hf-mirror.com -p 3000:8080 --add-host=host.docker.internal:host-gateway -v E:\ollama-web-ui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
安装路径:E:\ollama-web-ui
本地运行:Open WebUI
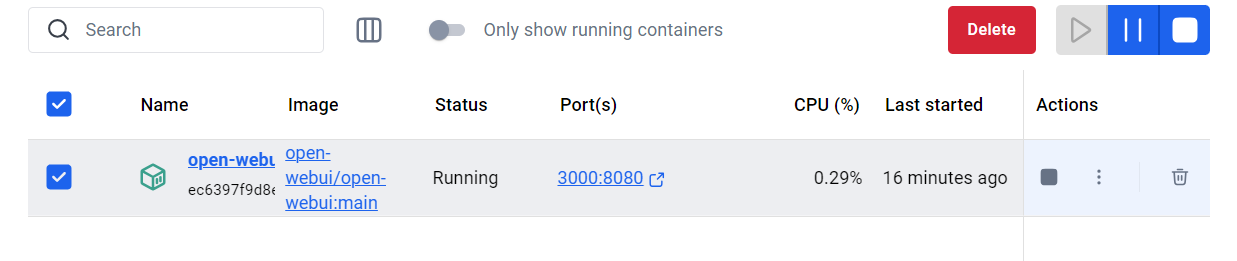
管理员账号:tt202502/1-6
交互界面AnythingLLM
和大模型的交互界面应用。
AnythingLLM是由 Mintplex Labs 开发的开源 AI 工具,可以将任何东西转换为您可以查询和聊天的训练有素的聊天机器人。
AnythingLLM 是一款 BYOK(自带密钥)软件,因此除了您想使用的服务外,此软件不收取订阅费、费用或其他费用。
AnythingLLM 是将强大的 AI 产品(如 OpenAi、GPT-4、LangChain、PineconeDB、ChromaDB 等)整合在一个整洁的包中而无需繁琐操作的最简单方法,可以将您的生产力提高 100 倍。
所有集合都组织成我们称之为“工作区”的桶。工作区是文件、文档、图像、PDF 和其他文件的存储桶,这些文件将被转换为 LLM 可以理解和在对话中使用的内容。 您可以随时添加和删除文件。
AnythingLLM 提供了两种与您的数据交流的方式:
查询:您的聊天将返回在您的工作区中访问的文档中找到的数据或推论。向工作区添加更多文档会使其更智能!
对话:您的文档和正在进行的聊天记录同时为 LLM 知识做出贡献。非常适合添加基于文本的实时信息或纠正 LLM 可能存在的误解。 您可以在聊天过程中切换模式!
AnythingLLM就像一个包壳的web应用(后来查了下,确实是)。AnythingLLM 得具备一定的程序思维,给技术人员用的。非技术人员还是使用cherry吧。作为喜欢折腾的开发人员,我们可以结合dify使用。
https://github.com/Mintplex-Labs/anything-llm
https://mp.weixin.qq.com/s/fX1UVCgAJbGtZH46EF0usQ
https://mp.weixin.qq.com/s/IKoBga2iKfpkdD4Qgy8iLg
问题:anythingllm documents failed it add.
解决:设置向量模型
anything llm无法上传文档解决办法_anythingllm embedder-CSDN博客
交互界面Dify
和大模型的交互界面应用。
Dify是基于LLM的大模型知识库问答系统,里面集成DeepSeek以及私有知识库,而Dify采用Docker的方式来安装。
https://github.com/langgenius/dify
阿里云镜像源无法访问?使用 DaoCloud 镜像源加速 Docker 下载
安装路径:E:\dify-main
tt202502/1-6abc
cp .env.example .env
docker compose up -d

问题:访问localhost/signin,被重定向。
解决:修改E:\apache\Apache24\conf,停止监听80端口,在任务管理器/服务,重启Apache服务。
向量模型bge-large
向量模型,把自然语言转为向量(一串数字)。能够理解自然语言的意思,语义相近的句子转换成的向量也接近。能够处理复杂的文字信息。能够处理多种语言。
ollama pull bge-large

chunk_size 分块大小
要求分块大小 < embedding模型极限
分块太大,抓不住细节。分块太小,切太碎,上下文不连贯。
chunk_overlap 分块重叠
相邻块的重叠部分。
Max Embedding Chunk Length 最大嵌入分块长度
查看embedding模型极限

在AnythingLLM中,设置该参数在设置-Embedder嵌入首选项-选择模型-设置Max Embedding Chunk Length。
TopK 检索时返回的最大相关块的匹配数量
即每次检索从所有的向量片段中返回多少个与Query最相似的片段。
TopK 值过大,会增加计算成本、引入噪声干扰、稀释关键信息。
TopK过小,信息不完整,性能受限。
Similarity_threshold 相似度阈值
LLM首选项
Context length 上下文窗口大小
Max Tokens依然要根据模型本身的能力上限来设置。

Temperature 控制生成答案的随机性
越高越多样化,越低越确定。
Top_p
基于概率的筛选参数,限制生成内容的范围。
https://mp.weixin.qq.com/s/yHQcBlZ7o4DmuSwB6ER2Kg
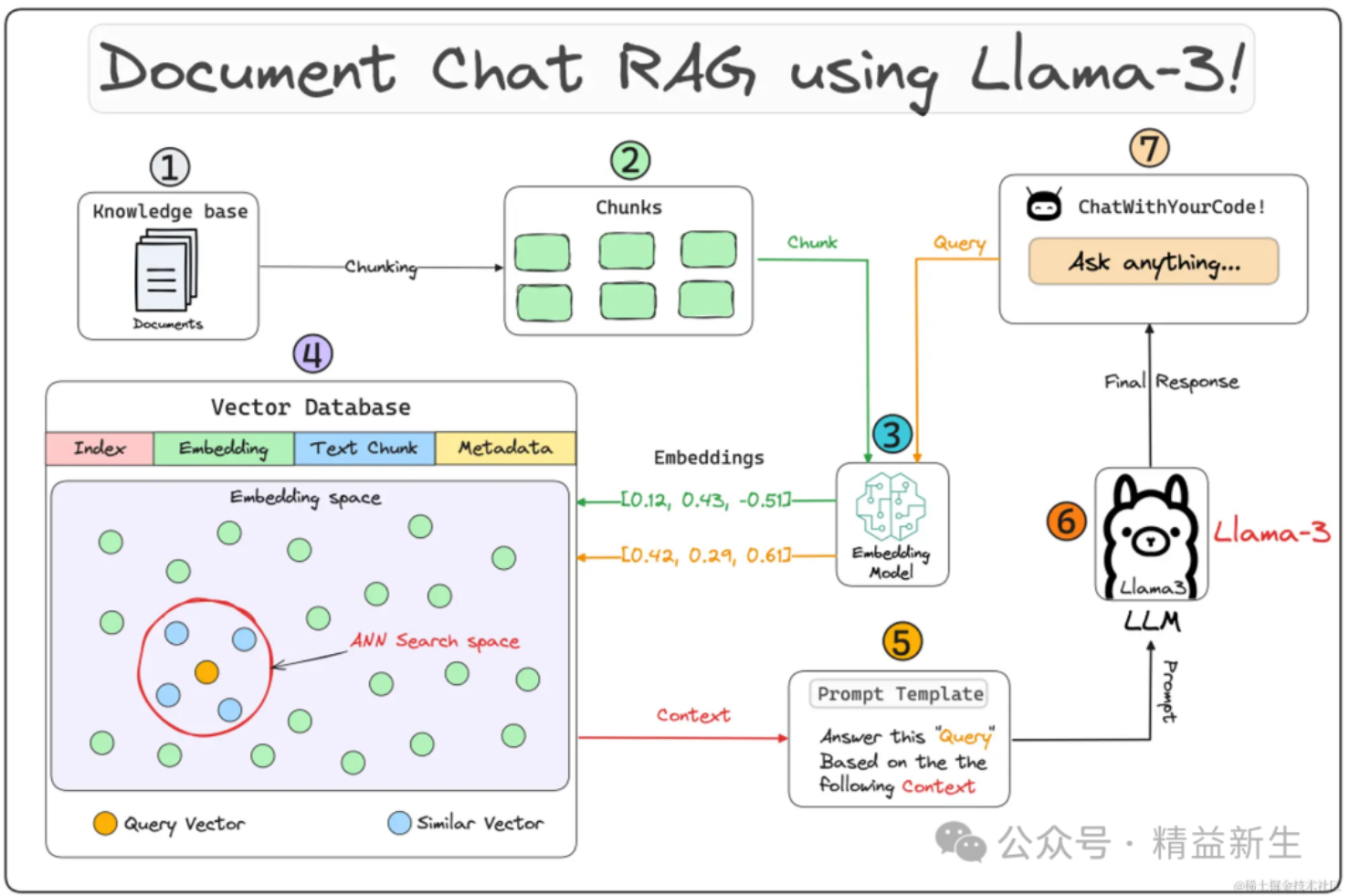
Qwen-Coder
生成代码
{kind=link}
{kind=link}